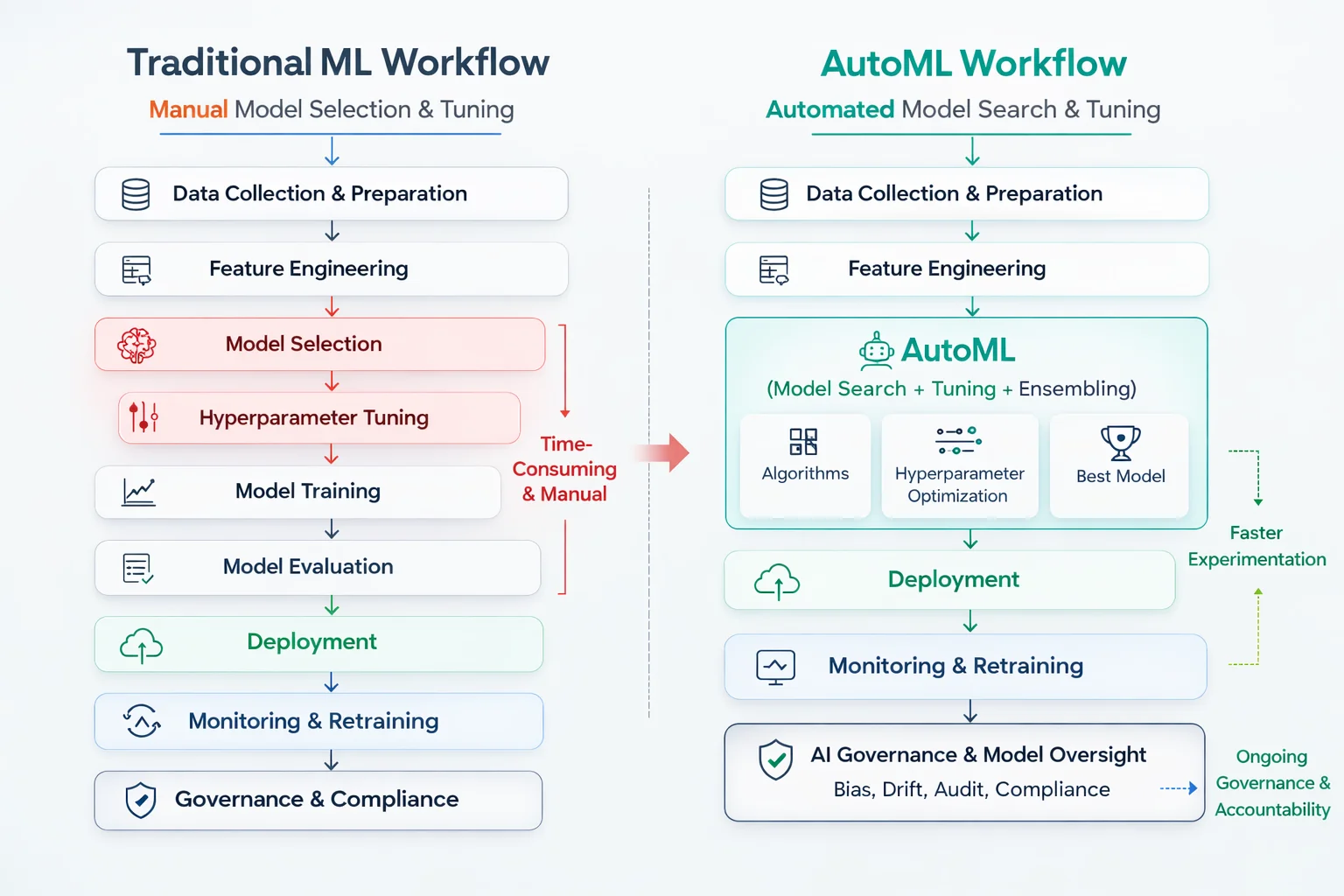
AutoML doesn't replace the ML lifecycle.
It compresses one specific stage of it.
Platforms like DataRobot make model experimentation incredibly efficient. You upload a dataset, and the platform automatically explores multiple algorithms, tunes hyperparameters, and can even produce ensemble (blender) models. What traditionally required significant manual experimentation can now happen much faster.
But when we started recreating a similar workflow using services like Amazon SageMaker and other AWS components, I observed something interesting.
The model search stage becomes dramatically easier, but the surrounding system remains just as important. In a traditional ML workflow, a large portion of the effort goes into algorithm selection, model experimentation, and hyperparameter tuning. With AutoML, that middle stage becomes far more streamlined.
What AutoML Doesn't Automate
Several critical parts of the pipeline still require careful engineering and decision-making:
Cleaning datasets, handling missing values, preventing data leakage, and deciding which features should actually enter the model.
Accuracy alone is rarely enough. The metric must match the real business outcome you are optimizing for.
AutoML can output probabilities, but converting those probabilities into real decisions requires defining risk thresholds and trade-offs.
Integrating models into APIs, batch pipelines, dashboards, or decision workflows that people or systems actually rely on.
Tracking performance over time, detecting data drift, and deciding when models need retraining.
Keeping track of model versions, training data, and decision history to ensure accountability and reproducibility.
In many real systems, the hardest part is not training the model but designing the decision logic around it.
AutoML accelerates model discovery, but building reliable ML systems is still largely about data quality, system design, and how predictions are used in real decisions.
I see AutoML less as a replacement for ML engineering and more as a powerful accelerator within the broader ML pipeline.
Curious how others see this balance between AutoML and custom ML pipelines. For teams that have used both managed AutoML platforms and custom ML pipelines, where do you see the biggest value?