Accuracy tells you how often your model is right.
It does not tell you whether being right matters in the way you think.
When you are building a lead scoring model to prioritize which insurance applicants to contact first, a model with 90% accuracy sounds compelling. But if 85% of your leads are easy rejections, a model that predicts "low priority" for everything achieves that accuracy without ever surfacing a single good lead.
This is not a hypothetical. It is exactly the kind of failure mode that shows up when teams treat model evaluation as a technical checkbox rather than a business alignment problem.
The Lead Scoring Context
At CloudFountain Inc., we built models to prioritize leads and predict placement approval rates. The decisions driven by these models had direct revenue implications. Contact the wrong leads first and sales capacity is wasted. Misprioritize approvals and the pipeline stalls. In that context, choosing the wrong evaluation metric is not just a technical error. It is a business error.
Metrics That Actually Matter
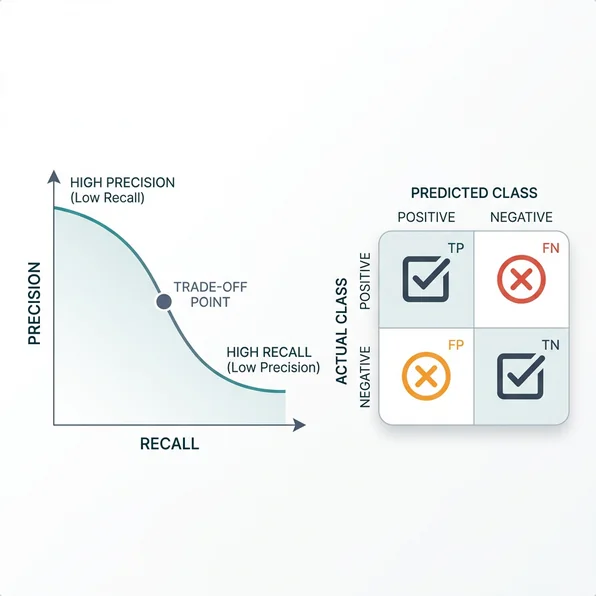
If contacting an unqualified lead wastes a sales rep's time and erodes trust, optimize for precision. You want your model to be highly confident before it flags a lead as high priority.
If your market is thin and every qualified lead matters, optimize for recall. Missing a good lead is more expensive than occasionally working a marginal one.
F1 gives you the harmonic mean of precision and recall. Useful when both false positives and false negatives carry meaningful cost. We used this as our primary optimization target, then adjusted the decision threshold post-training.
These rank-order metrics tell you how well your model separates classes across all possible thresholds. AUC-PR is especially useful for imbalanced datasets, which is common in lead scoring where good leads are rare.
The threshold is a business decision, not a model decision. Choosing 0.5 as your default classification cutoff is almost always wrong. Set it based on the cost ratio of false positives to false negatives in your specific context.
What We Changed
We moved away from reporting accuracy as our headline metric entirely. Instead, our dashboards showed precision, recall, and F1 by lead segment. We also tracked business outcomes downstream: contact rates, placement rates, and sales cycle length. Model performance was measured against those, not just against holdout accuracy.
We also introduced separate evaluation thresholds for different use cases. A model driving automated email sequencing had a different precision requirement than a model providing real-time agent recommendations. Same model, different operating points.
The Broader Point
Every ML system operates in a business context that has asymmetric costs. Missing a high value customer is rarely the same cost as incorrectly prioritizing a low value one. Your evaluation metric should encode that asymmetry explicitly.
Before you pick a metric, ask: what is the cost of a false positive in production, and what is the cost of a false negative? The answer to that question should drive your metric choice more than any best practice document.