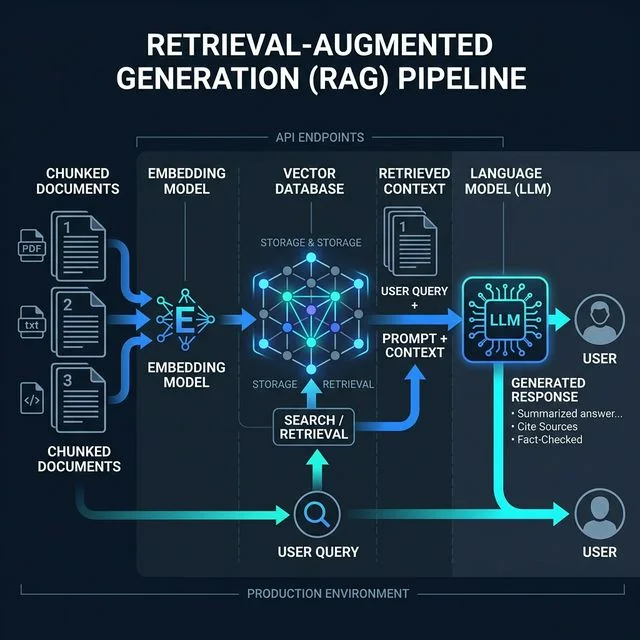
The retrieval part of RAG is where most
production failures actually live.
We integrated a RAG-based assistant into an internal tool at CloudFountain. The use case was straightforward: agents needed fast, accurate answers from a large set of policy documents that changed frequently. A vector search over embedded chunks, a call to an LLM with the retrieved context, a clean answer. Simple enough in theory.
What followed was six weeks of debugging problems that had nothing to do with the language model and everything to do with how retrieval actually works at the edges.
The Retrieval Gap
The single most underestimated problem in RAG is retrieval quality. If the right chunk is not in the top-k results, no amount of prompt engineering will fix the answer. The model can only work with what you give it.
We tried fixed-size chunking first. 512 tokens, 256 tokens, 128 tokens. None worked consistently because policy documents have logical sections that span arbitrary lengths. Switching to semantic chunking, splitting on headings, paragraphs, and clause boundaries, improved retrieval precision significantly without touching the model.
The embedding model you choose encodes a particular notion of similarity. A model trained on general web text performs very differently on domain-specific legal or policy language. We tested three embedding models against the same query set before picking one. The accuracy difference between the best and worst was over 30 percentage points on hard queries.
Vector search is great for semantic queries. It struggles with exact lookups: specific clause numbers, acronyms, proper nouns. We combined vector similarity with BM25 keyword search using a reciprocal rank fusion approach. Retrieval recall improved without a meaningful latency penalty.
Retrieve more chunks than you need (top-20), then run a cross-encoder re-ranker to select the best 5 before passing to the LLM. The re-ranker sees the query and each chunk together, giving it much more signal than the initial embedding comparison. The added latency was around 80ms and the answer quality improvement was noticeable.
Most RAG failures are retrieval failures dressed up as generation failures. Before tuning prompts, measure whether the right context is actually being retrieved.
The Production Problems Nobody Demos
Documents change. When they do, the embeddings in your vector store go stale. We needed a pipeline that detected document changes, re-chunked affected files, deleted the old vectors, and inserted new ones, without rebuilding the entire index. This took longer to build than the original ingestion pipeline.
RAG systems have no concept of "I don't know." If you retrieve something plausible and pass it to the model, you often get a confident-sounding hallucination. We added a confidence scoring step that checked retrieval scores against a threshold and returned a fallback response rather than fabricating answers from low-confidence context.
Embed the query, retrieve from vector DB, optionally re-rank, call the LLM. Each step adds latency, and they stack sequentially. We implemented async retrieval where possible and cached embeddings for repeated queries. For frequently asked questions, we cached the full response behind a similarity threshold check against prior queries.
Building RAG for production is mostly an infrastructure and data quality problem. The language model is the easy part. What surrounds it, the ingestion pipeline, the retrieval strategy, the freshness checks, the fallback logic, is where the real engineering lives.
If you are just starting to build a RAG system, measure your retrieval quality first. Build an evaluation set of real queries with known correct chunks before you write a single line of prompt engineering.